

De hoeveelheid data binnen organisaties groeit explosief. Nieuwe applicaties, klantinteracties, sensoren, drones en digitale processen zorgen dagelijks voor een continue stroom aan gegevens. Managers zien steeds vaker dat data een sleutelrol speelt in het verbeteren van dienstverlening, het vergroten van efficiency en het ontwikkelen van nieuwe verdienmodellen. Maar waar data kansen biedt, brengt het ook uitdagingen met zich mee.
Zonder duidelijke structuur verandert de datastroom al snel in een onoverzichtelijke brij. Afdelingen verzamelen en gebruiken hun eigen datasets, vaak los van elkaar en zonder afstemming. Het gevolg: dubbele inspanningen, inconsistente inzichten en een datalandschap dat steeds lastiger te beheren wordt. Tegelijkertijd neemt de druk op centrale datateams toe, die alle verzoeken niet meer kunnen bijbenen.
Een goede data-architectuur zorgt voor het kunnen omgaan met deze uitdagingen
Data-architectuur gaat over het slim organiseren van gegevens, zodat ze vindbaar, betrouwbaar en bruikbaar zijn. Dat vraagt niet alleen om technische oplossingen, maar ook om duidelijke afspraken in de organisatie. Hoe richt je eigenaarschap in? Hoe deel je data slim? En hoe borg je kwaliteit?
Een goede data-architectuur is onmisbaar. Het legt de basis voor innovatie én voor efficiënte bedrijfsvoering. In dit artikel nemen we de lezer mee langs de belangrijkste bouwstenen van moderne data-architectuur. We starten met de bekende technologieën en kijken daarna naar de nieuwere concepten data mesh en data fabric, die vooral gaan over de manier waarop data in de organisatie wordt gedeeld en beheerd. Zo krijgen managers een helder overzicht van mogelijkheden, valkuilen en praktische handvatten om in hun organisatie optimaal gebruik te kunnen maken van data & AI.
2 Data architectuur
De perfecte inrichting van een dataorganisatie ontstaat niet vanzelf. Dit begint bij de strategische doelen van de organisatie: wat wil je bereiken met data & AI? Bijvoorbeeld sneller inspelen op klantbehoeften, operationele processen efficiënter maken of nieuwe producten ontwikkelen. Vanuit die doelen volgen eisen voor hoe data wordt verzameld, opgeslagen, gedeeld en beheerd.
Hier komt data-architectuur in beeld. Data-architectuur is het geheel aan keuzes en kaders dat organisaties helpt om hun datadoelen waar te maken. Het gaat daarbij niet alleen om technische keuzes – zoals welke opslagtechnologie je gebruikt – maar ook om organisatorische aspecten zoals eigenaarschap, datakwaliteit en governance. Architectuurprincipes zorgen ervoor dat deze keuzes altijd in lijn blijven met de strategie van de organisatie.
Zonder data-architectuur ontstaat er al snel versnippering. Afdelingen ontwikkelen hun eigen oplossingen, gebruiken verschillende definities en hanteren uiteenlopende standaarden. Het resultaat: inefficiëntie, hogere kosten en een gebrek aan vertrouwen in de data. Een goede data-architectuur voorkomt dit door samenhang te brengen tussen technologie, organisatie en dienstverlening.
Daarmee vormt data-architectuur de brug naar de thema’s die in dit artikel centraal staan. Aan de technologische kant helpt data-architectuur bepalen welke oplossingen (zoals een datawarehouse, datalake of datalakehouse) passen bij de behoeften van de organisatie. Aan de organisatorische kant biedt architectuur richting hoe data wordt gedeeld en beheerd, bijvoorbeeld met behulp van concepten als data mesh en data fabric. Samen zorgen deze elementen ervoor dat data niet alleen beschikbaar is, maar ook daadwerkelijk waarde toevoegt voor de organisatie.
3 Waardevolle technologieën voor het gebruiken van data
Organisaties hebben vandaag de dag meerdere technologieën tot hun beschikking om waarde uit data te halen: data warehouse, datalake en datalakehouse. Elk van deze oplossingen heeft een eigen rol en toepassingsgebied. Waar enerzijds de behoefte ligt bij betrouwbare rapportages en consistente analyses, kunnen anderzijds flexibiliteit, snelheid en het kunnen combineren van uiteenlopende databronnen een belangrijke rol spelen. Hierdoor gebruiken organisaties niet langer één oplossing, maar zetten zij verschillende technologieën naast of in combinatie met elkaar in. Het datawarehouse vormt nog steeds de stabiele basis voor betrouwbare informatievoorziening, terwijl datalakes en lakehouses juist inspelen op de groeiende behoefte om ook ongestructureerde data te benutten en nieuwe vormen van analyse mogelijk te maken.
3.1 Datawarehouse; betrouwbare basis voor analyse
Toen organisaties steeds meer digitale gegevens verzamelden, ontstond de behoefte aan een centrale plek waar informatie uit verschillende systemen werd samengebracht voor rapportage en besluitvorming. Zo ontstond het datawarehouse: een gestructureerde omgeving waarin data wordt opgeschoond, gestandaardiseerd en voorbereid voor analyse.
Het grote voordeel van een datawarehouse is betrouwbaarheid. In tegenstelling tot operationele systemen (die vooral transacties en dagelijkse processen ondersteunen) is een datawarehouse specifiek ontworpen voor analyse en trendonderzoek. Denk aan financiële rapportages, verkoopanalyses of klantinzichten. Tot op de dag van vandaag is het de ruggengraat van veel BI-omgevingen: stabiel, controleerbaar en gericht op consistente informatievoorziening.
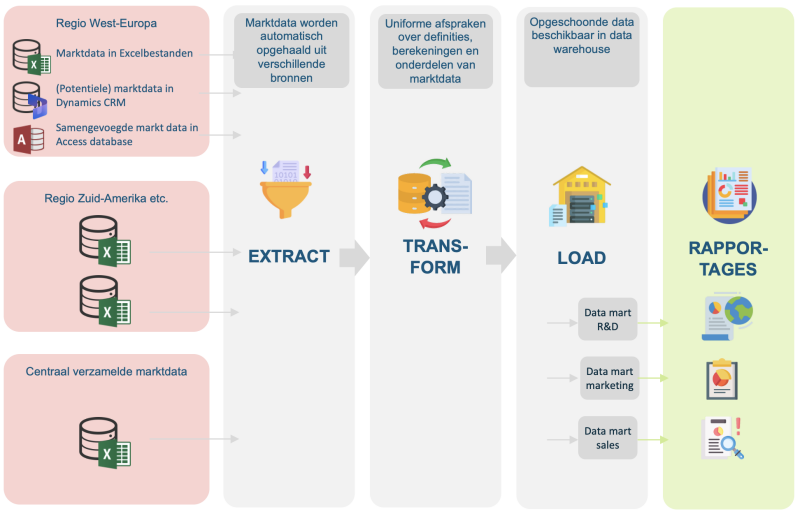
Een datawarehouse is vooral geschikt als een organisatie grote hoeveelheden historische gegevens uit verschillende bronnen wil samenbrengen en omzetten naar betrouwbare inzichten. Dat gebeurt via een proces van Extract, Transform, Load (ETL):
- Extract – Gegevens worden opgehaald uit verschillende bronnen (bijvoorbeeld lokale Excel-bestanden, CRM-systemen of centrale databases)
- Transform – De data wordt opgeschoond, geharmoniseerd en verrijkt (bijvoorbeeld door uniforme definities en berekeningen vast te leggen)
- Load – De bewerkte data wordt opgeslagen in het data warehouse en beschikbaar gemaakt voor dashboards, rapportages en analyses
Het resultaat is één centrale bron van waarheid. Alle teams werken met dezelfde definities en betrouwbare cijfers, wat niet alleen efficiëntie oplevert maar ook vertrouwen in de data vergroot.
Een data warehouse biedt stabiliteit en betrouwbaarheid, maar heeft ook beperkingen. Het is vooral gericht op gestructureerde data en kan minder goed omgaan met de enorme diversiteit aan ongestructureerde gegevens die tegenwoordig beschikbaar is, denk aan tekstbestanden, afbeeldingen, audio, video of social media. Om te voorzien in die behoefte behandelen we hierna het datalake.
Kader: Voorbeeld uit de praktijk – datawarehouse bij een zaadveredelaar
Een van de grootste uitdagingen voor een internationale zaadveredelaar was het creëren van betrouwbare marktinzichten. Data werd in verschillende landen en afdelingen verzameld, vaak in losse Excel-bestanden of lokale databases. Daardoor was het moeilijk om trends te vergelijken en strategische keuzes te onderbouwen.
Met de invoering van een datawarehouse kreeg het bedrijf grip op haar marktdata. Alle bronnen werden centraal verzameld, opgeschoond en voorzien van heldere definities. Hierdoor konden verschillende afdelingen – van R&D tot sales en management – werken vanuit dezelfde inzichten.
De voordelen waren duidelijk:
- Betrouwbare en herleidbare marktdata: alle data met duidelijke herkomst en definities
- Vergelijkbare inzichten: uniforme cijfers tussen landen, regio’s en productgroepen
- Ondersteuning van strategische keuzes: beter zicht op marktaandeel, groeipotentieel en klantbehoeften
- Één centrale bron van waarheid: minder versnippering en meer consistentie in besluitvorming
Het datawarehouse werd zo het fundament onder alle analyses, rapportages en strategische beslissingen van de organisatie.
3.2 Datalake; flexibiliteit voor diverse databronnen
Nieuwe technologieën, IoT, drones en social media zorgen ervoor dat organisaties steeds meer verschillende soorten data willen analyseren. Naast gestructureerde gegevens, zoals verkoopcijfers of klantinformatie, groeit de behoefte om ook ongestructureerde data te benutten, zoals afbeeldingen, video’s, logbestanden en tekst. Het traditionele data warehouse is hiervoor minder geschikt, waarop het datalake een waardevolle aanvulling vormt.
Een data lake speelt in op de zogeheten 5 V’s van data. Waar traditionele datawarehouses vooral zijn ontworpen voor betrouwbaarheid en gestructureerde data, biedt het lake ruimte aan de groeiende volumes data (Volume), de steeds hogere verwerkingssnelheid (Velocity) en de grote variatie aan databronnen (Variety). Die flexibiliteit maakt het mogelijk om data uit uiteenlopende bronnen op één plek te combineren.
Tegelijk vraagt dit om aandacht voor datakwaliteit (Veracity) en het creëren van waarde (Value),
Wanneer kies je voor een datalake?
Een datalake is vooral waardevol wanneer organisaties:
- Werken met veel verschillende databronnen en/of ongestructureerde data zoals ongestructureerde sensorgegevens, documenten of klantreviews
- Ruimte willen voor experiment en verkenning, bijvoorbeeld voor data scientists die AI-modellen of machine learning-algoritmes ontwikkelen
- Grote hoeveelheden data goedkoop en schaalbaar willen opslaan, als nog niet duidelijk is hoe die data later gebruikt gaat worden
- Analyses nodig hebben die verder gaan dan rapportages, zoals voorspellingen, patroonherkenning of anomaly detection
Voorbeelden uit de praktijk:
- Een logistiek bedrijf dat sensordata van duizenden vrachtwagens analyseert om onderhoud te voorspellen. Omdat deze sensordata in de context van andere sensoren waardevol is, waarbij er geen specifiek datamodel wordt gevolgd door de verschillende databronnen, is een datalake een uitstekende oplossing om deze gebrek aan structuur op te vangen.
- Een bank die transactiegegevens combineert met e-mails en social media om fraude op te sporen.
- Een e-commerce speler die klikgedrag, klantrecensies en productafbeeldingen samenbrengt voor gepersonaliseerde aanbevelingen
Een datalake biedt veel flexibiliteit, maar kent ook uitdagingen. Omdat data in ruwe vorm wordt opgeslagen, is het bewaken van orde en kwaliteit niet altijd eenvoudig. Om deze beperkingen te ondervangen combineren organisaties steeds vaker de betrouwbaarheid van een datawarehouse met de flexibiliteit van een datalake: een zogeheten datalakehouse.
Kader: Blauwdruk van een datalake
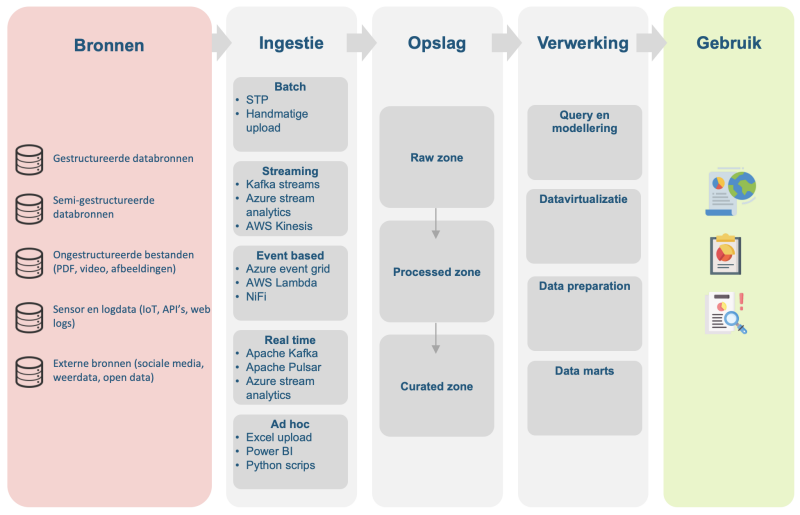
Een datalake klinkt misschien als één grote bak waarin alle ruwe data zomaar wordt opgeslagen, maar in werkelijkheid is het een flexibel systeem dat ruimte biedt aan data met uiteenlopende structuren. Om waarde te kunnen halen uit deze diversiteit, is het belangrijk om orde en samenhang aan te brengen. Een goed ingericht lake bevat daarom voorzieningen om data vindbaar, beheersbaar en betrouwbaar te houden. De belangrijkste bouwstenen:
1. Bronnen – de toevoer van data
Datalakes krijgen hun kracht doordat ze uiteenlopende databronnen kunnen ontvangen: van traditionele databases en ERP-systemen tot sensoren in machines, klantreviews of social-mediafeeds. Deze diversiteit maakt het mogelijk om verbanden te leggen die in afzonderlijke bronnen onzichtbaar zouden blijven.
2. Ingestie – de poortwachter
De ingestielaag bepaalt hoe data binnenkomt. Dat kan in één keer (batch), continu (streaming) of real-time, afhankelijk van de behoefte. Belangrijk is dat er altijd metadata wordt meegeleverd: informatie over de herkomst, het tijdstip of het formaat van de data. Dit zorgt ervoor dat later nog te herleiden is waar de data vandaan komt en hoe actueel deze is.
3. Opslag – het hart van het lake
In de opslaglaag krijgt data een plek, meestal in de cloud. Om orde te houden wordt vaak gewerkt met zones: een ruwe laag waar alles binnenkomt, een opgeschoonde laag voor gecorrigeerde data en een curated laag waarin data klaarstaat voor gebruik. Deze structuur voorkomt dat het lake verandert in een ondoordringbaar “data-moeras”.
4. Verwerking – de keuken van het lake
Hier wordt data bewerkt: fouten worden hersteld zodat de data van de ruwe laag naar de opgeschoonde laag overgebracht kunnen worden. Vervolgens worden gegevens samengevoegd of verrijkt met externe informatie en algoritmes kunnen patronen ontdekken. Deze verrijkte (en gestructureerde) data worden vervolgens opgeslagen in de curated laag. Van simpele omzettingen tot geavanceerde AI-modellen. De verwerking maakt van ruwe data een bruikbaar ingrediënt.
5. Gebruik – waar waarde ontstaat
De echte kracht van een datalake komt naar voren wanneer gebruikers ermee aan de slag gaan. Data scientists kunnen modellen trainen, analisten bouwen dashboards en managers krijgen inzichten die helpen bij besluitvorming. Zonder deze stap is een lake slechts opslag. Mét deze stap wordt het een bron van innovatie.
Kortom: een datalake is geen losse technologie, maar een samenhangend ecosysteem. Wie de onderdelen goed op elkaar afstemt, creëert een omgeving waarin data niet alleen wordt bewaard, maar vooral ook benut.
3.3 Datalakehouse; flexibiliteit én betrouwbaarheid
Zowel het datawarehouse als het datalake hebben hun waarde bewezen en worden nog vaak ingezet als oplossing voor datavraagstukken. Het warehouse blinkt uit in structuur en betrouwbaarheid, ideaal voor gestructureerde data zoals klantgegevens of financiële transacties. Een datalake biedt juist flexibiliteit en schaalbaarheid, waardoor ook ongestructureerde data zoals video’s, ongestructureerde sensordata en teksten kan worden opgeslagen.
Tegelijkertijd hebben beide nadelen: een warehouse kan niet goed omgaan met moderne databronnen, terwijl een datalake zonder strakke inrichting kan verworden tot een “data swamp”: een onoverzichtelijk moeras waarin data lastig vindbaar of betrouwbaar is.
Om dit te voorkomen kunnen organisaties kiezen voor een datalakehouse. Dit combineert eigenschappen van beide werelden: de flexibiliteit van een datalake, mét de kwaliteitsborging en gestructureerde analysemogelijkheden van een warehouse.
Waarom kiezen voor een datalakehouse?
Een datalakehouse wordt vaak interessant wanneer:
- Data is versnipperd over verschillende systemen en bronnen. Een lakehouse brengt dit samen in één omgeving, ongeacht type data
- Kostenbeheersing is belangrijk. Een lakehouse gebruikt vaak goedkope opslag, maar behoudt toch de analysekracht van een warehouse
- Nieuwe databronnen zoals video’s, sensordata of IoT spelen een grote rol. Een lakehouse kan deze combineren met traditionele datasets
Het resultaat is een platform dat flexibel is waar het kan, en gestructureerd waar het moet. Zo kan een organisatie sneller waarde halen uit uiteenlopende databronnen, zonder concessies te doen aan betrouwbaarheid of kwaliteit.
Net als bij de andere twee vraagt een datalakehouse om zorgvuldige inrichting en duidelijke governance. Zonder heldere afspraken over datakwaliteit, eigenaarschap en toegang kan een datalakehouse te complex worden. Voordelen gaan dan verloren.
Met het datalakehouse beschikken organisaties over een krachtige technologie. Maar techniek alleen is niet genoeg. Het gaat er ook om hoe data slim wordt georganiseerd, gedeeld en beheerd binnen de organisatie. Daar komen data mesh en data fabric om de hoek kijken.
Kader: Nieuwe inzichten door slim combineren van data bij een luchtvaartmaatschappij
Een grote luchtvaartmaatschappij verwerkt dagelijks enorme hoeveelheden data. Gestructureerde data zoals boekingssystemen, vluchtschema’s en klantprofielen werden traditioneel in een warehouse opgeslagen. Ongestructureerde data van vliegtuigen, socialmediaberichten en e-mails van de klantenservice kwamen in een datalake terecht.
Dit zorgde voor knelpunten:
- Moeizame integratie van gegevens uit de verschillende systemen
- Trage analyses door duplicatie en verspreide opslag
- Beperkte mogelijkheden om real-time inzichten te genereren
Met een datalakehouse bracht de luchtvaartmaatschappij alles samen op één platform, met behulp van technologieën als Delta Lake, Azure Synapse en Databricks. Hierdoor ontstonden nieuwe toepassingen:
- Predictief onderhoud: trillingsdata uit sensoren werd gekoppeld aan onderhoudslogboeken en vluchtschema’s. Zo kon het bedrijf voorspellen wanneer onderdelen defect dreigden te raken, wat kosten bespaarde en veiligheid verhoogde
- Klantinzichten: door klantfeedback van social media te combineren met vluchtdata en klantprofielen kreeg de maatschappij inzicht in factoren die klanttevredenheid beïnvloeden, tot op het niveau van specifieke routes of toesteltypen
Het datalakehouse bood de luchtvaartmaatschappij daarmee niet alleen efficiency, maar ook geheel nieuwe mogelijkheden om waarde te creëren uit data.
4 Techniek alleen is niet genoeg, daarvoor is ook de organisatiekant van data nodig
Naarmate de vraag naar data groeit, lopen centrale teams steeds vaker vast: ze krijgen meer verzoeken dan ze aankunnen, waardoor vertragingen ontstaan en afdelingen hun eigen oplossingen gaan bouwen. Het gevolg is schaduw-IT, dubbele inspanningen en een gebrek aan overzicht.
Daarom zijn er ook concepten nodig die helpen om data slimmer te organiseren en toegankelijk te maken. Twee benaderingen die hierbij een rol spelen zijn data mesh, een organisatorisch concept dat eigenaarschap verdeelt over domeinen, en data fabric, een technologisch patroon dat databronnen integreert tot één samenhangend geheel.
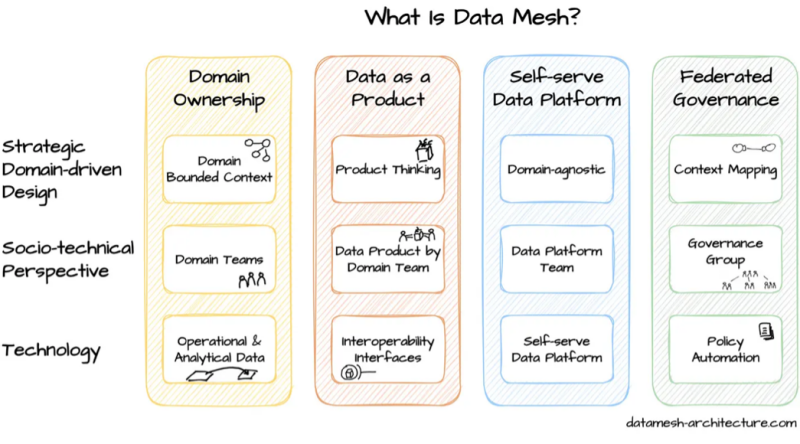
4.1 Data Mesh; eigenaarschap in de business
Data mesh is een manier om data te organiseren waarbij de verantwoordelijkheid niet langer alleen bij één centraal team ligt. In plaats daarvan wordt de verantwoordelijkheid verdeeld over verschillende domeinen of afdelingen. Elk domein beheert zijn eigen data als een “product” dat door anderen kan worden gebruikt.
Dit werkt vooral goed bij grote organisaties met veel verspreide databronnen, zelfstandige afdelingen en een overbelast centraal datateam. Door de verantwoordelijkheid dichter bij de bron te leggen, ontstaat meer flexibiliteit en snelheid. Teams kunnen sneller nieuwe data-oplossingen ontwikkelen en tegelijk profiteren van gedeelde standaarden waarbij de ontwikkeldruk op het centrale datateam wordt verlicht.
Randvoorwaarden voor succes
Om data mesh te laten werken, moet een organisatie aan enkele voorwaarden voldoen:
- Duidelijke datadomeinen: data wordt ingedeeld naar logische bedrijfsonderdelen (bijv. Finance, Sales, Operations), elk met een duidelijke eigenaar
- Dataproducten als bouwstenen: elk domein levert dataproducten die door anderen kunnen worden gebruikt, zoals omzet per productcategorie of klantsegmentatie. Deze producten moeten goed beschreven, betrouwbaar en eenvoudig bruikbaar zijn
- Een self-service platform: teams moeten hun dataproducten zelfstandig kunnen bouwen en beheren, zonder afhankelijk te zijn van een centraal team
- Heldere afspraken en standaarden: ondanks decentralisatie moeten organisaties zorgen voor gedeelde spelregels, zodat data eenduidig en vergelijkbaar blijft
- Een datacultuur: data wordt gezien als strategische asset. Teams zijn verantwoordelijk voor de kwaliteit van hun eigen dataproducten
- Data-vaardigheden in de teams: elk domein moet voldoende kennis hebben om data goed te begrijpen en toe te passen
Data mesh vraagt dus om een volwassen organisatie, met duidelijke domeinindeling en een sterke datacultuur.
4.2 Data fabric; één geïntegreerde datalaag
Waar data mesh inzet op decentralisatie, richt een data fabric zich juist op het slim verbinden van bestaande databronnen in één geïntegreerde laag. Het doel is dat gebruikers, technisch of niet-technisch, eenvoudig toegang hebben tot data, zonder dat bestaande systemen hoeven te worden vervangen. Dit vermindert de beperkende factor die legacy systemen hebben op de data-ambities van de organisatie. Terwijl deze ambities worden waargemaakt, kunnen verouderde systemen waar nodig stapsgewijs worden uitgefaseerd.
Data fabric maakt gebruik van metadata en AI om gegevens uit verschillende systemen automatisch vindbaar en bruikbaar te maken. Analisten kunnen sneller rapporteren, data-engineers kunnen sneller koppelingen leggen en managers krijgen sneller inzicht in de data die er al is.
Randvoorwaarden voor succes
Voor een goed werkende data fabric zijn de volgende elementen essentieel:
- Sterke metadata: hoe beter en vollediger de metadata, hoe makkelijker data vindbaar wordt
- Kennis in huis: expertise is nodig om een fabric te ontwerpen, op te zetten en te beheren
- Centrale controle: ondanks de flexibiliteit kiest een organisatie bij het gebruik van fabric voor gecentraliseerd (meta)datamanagement, zodat consistentie behouden blijft
- Geschikt voor minder complexe organisaties: een data fabric is vooral waardevol als er minder behoefte is aan decentrale verantwoordelijkheid, maar wél aan betere toegankelijkheid van data.
Mesh of Fabric?
Beide concepten hebben hetzelfde doel: meer waarde halen uit data zonder dat het centrale datateam overbelast raakt. Het verschil zit in de aanpak:
- Een data mesh legt verantwoordelijkheid neer bij de businessdomeinen, en werkt goed in grote organisaties met veel decentrale afdelingen
- Een data fabric zorgt vooral voor slimme integratie en toegankelijkheid, zonder de organisatie sterk te hoeven veranderen
Welke aanpak het meest geschikt is, hangt dus af van de organisatiecultuur, complexiteit en volwassenheid.
Vergelijking tussen data mesh en data fabric | ||
Eigenschap | Data Mesh | Data Fabric |
Eigenaarschap | Gedecentraliseerd, domein specifiek | Gedecentraliseerd naar de daarvoor afgesproken standaarden |
Governance | Gefedereerd. Zowel lokaal als globaal beleid | Gecentraliseerd, uniforme governance afspraken |
Data benadering | Data as product door domein eigenaren | Geautomatiseerde data integratie laag |
Architectuur | Gedistribueerde microservices en pipelines | Uniforme data virtualisatie laag en centrale data services |
Implementatie | Vereist organisatorische verandering richting datadomeinen | Technologisch gefocust |
Passendheid | Grote, complexe, autonome domeinen met eigen dataproducten | Voorkeur voor gecentraliseerde control en productie |
5. Conclusie
Data is vandaag de dag onmisbaar voor organisaties. Maar de waarde van data ontstaat niet vanzelf. Daarvoor zijn zowel de juiste technologieën als de juiste organisatie-inrichting nodig.
In dit stuk hebben we vijf belangrijke begrippen van data-architectuur nader verklaard:
- Het data warehouse als fundament voor betrouwbare rapportages en consistente analyses
- Het datalake als flexibele opslagplaats voor uiteenlopende databronnen, inclusief ongestructureerde data
- Het datalakehouse als moderne combinatie die flexibiliteit en betrouwbaarheid samenbrengt
- En de organisatorische concepten data mesh en data fabric, die laten zien dat eigenaarschap, samenwerking en toegankelijkheid minstens zo belangrijk zijn als de technologie erachter
De kernboodschap is dat er geen “one size fits all” oplossing bestaat. De juiste keuzes hangen af van de strategische doelen van de organisatie, de mate van complexiteit en de volwassenheid van teams en processen. Wie de balans vindt tussen technologische oplossingen en organisatiebrede afspraken, bouwt een data-architectuur die niet alleen vandaag werkt, maar ook toekomstbestendig is.
Voor managers betekent dit: het is niet nodig om de technische details te kennen, wél om te begrijpen wat de verschillen zijn tussen deze concepten en wanneer ze waarde toevoegen. Begin dus niet met de tool, maar met de vraag: wat wil je met data bereiken? Vanuit die strategische doelen kun je bepalen welke technologie en welke organisatievorm het beste passen.
Op die manier wordt data niet alleen een kostenpost of een ongestructureerde berg, maar een strategische asset die blijvend waarde toevoegt aan de organisatie.



